一般我們查看系統性能主要是在以下幾個方面
1.用戶使用CPU情況 展現為 %user
2.系統使用CPU情況 展現為 %sys
3.wio或iowait 展現為 %iowait 進程由於等待磁盤IO而使CPU處於空閒狀態的比率
4.CPU的空閒率
5.CPU上下文的交換的比率,也有說明為CPU上下文的切換。即內存和寄存器中數據的切換
6.nice 這個還不是很明白是啥意思
7.real-time 還是未知
8.運行隊列的長度
9.平均負載
二 常用命令
1.mpstat
2.top
3.vmstat
4.sar
5.iostat
6.uptime
三命令詳解
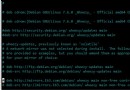
1. mpstat -P ALL 5 //需要注意的P和ALL一定要大寫
17時22分24秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
17時22分29秒 all 0.30 0.00 0.10 0.67 0.02 0.07 0.00 98.83 821.40
17時22分29秒 0 1.00 0.00 0.60 1.00 0.20 0.60 0.00 96.60 560.00
17時22分29秒 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.20 0.00
17時22分29秒 2 0.60 0.00 0.20 0.20 0.00 0.20 0.00 99.00 250.20
17時22分29秒 3 0.00 0.00 0.00 4.00 0.00 0.00 0.00 96.00 11.20
17時22分29秒 4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.20 0.00
17時22分29秒 5 0.80 0.00 0.00 0.00 0.00 0.00 0.00 99.20 0.00
17時22分29秒 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
17時22分29秒 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
上面信息我們可以看出,有8個CPU。
%user :在internal時間段裡,即為用戶態的CPU時間,及登錄用戶所消耗的CPU時間比。
%sys :在internal時間段裡,負進程消耗的CPU時間,占所有CPU的百分比
%nice :優先進程占用時間
%iowait:在internal時間段裡,所有未等待磁盤IO操作進程占CPU的百分比
%irq : 這個還是未知
%soft : 在internal時間段裡,軟中斷時間(%) softirq/total*100
%idle : 在internal時間段裡,CPU除去等待磁盤IO操作外的因為任何原因而空閒的時間閒置時間 (%)
intr/s: 在internal時間段裡,每秒CPU接收的中斷的次數
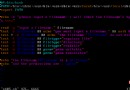
3.vmstat
procs ———–memory———- —swap– —–io—- -system– —–cpu——
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 1 1385712 66752 112164 1429992 3 4 14 50 14 2 10 2 88 1 0
1 0 1385712 64540 112208 1430976 0 0 3 104 2599 6595 15 2 81 3 0
0 0 1385712 62084 112232 1433008 0 0 1 1276 2068 7772 18 1 77 4 0
0 0 1385712 60808 112232 1434036 0 0 1 29 730 3686 9 1 90 1 0
參數詳解:
r:當前系統中等待CPU的進程數(所有的CPU),若是改值連續都大於CPU的個數,表明有多數進程在等待CPU進行處理。若是該值大於CPU個數4倍的話,那麼表明該服務器缺少CPU,或者CPU的處理速度過慢
in :cpu每秒產生的中斷數
cs :每秒產生的上下文切換
us:用戶占用的CPU時間百分比,同mpstat 的%user,說明用戶進程消耗的CPU時間多,但是如果長期超50%的使用,那麼我們就該考慮優化程序算法或者進行加速(比如PHP/PERL)
sy:系統占用的CPU時間百分比,同mpstat 的%sys。內核進程消耗的CPU時間百分比(sy的值高時,說明系統內核消耗的CPU資源多,這並不是良性表現,我們應該檢查原因)
id:CPU處於空閒狀態時間百分比,如果空閒時間(cpu id)持續為0並且系統時間(cpu sy)是用戶時間的兩倍(cpu us) 系統則面臨著CPU資源的短缺.
wa:IO等待消耗的CPU時間百分比,wa的值高時,說明IO等待比較嚴重,這可能由於磁盤大量作隨機訪問造成,也有可能磁盤出現瓶頸(塊操作)。
us+sy+id = 100%
常見用法:
vmstat -n 3 //每三秒獲取一次數據
vmstat 4 5 //間隔4次輸出5次數據
概念詳解:
上下文切換:CPU的切換就是將輪到該時間片的進程,將該進程中的數據從內容中刷到CPU的寄存器中,同時將原寄存器中的數據刷到內存中保存。
4.sar
sar [options] [-A] [-o file] t [n]
t 和 n兩個參數指定了采樣間隔和采樣次數
- o 較日志記錄到某個文件中
sar 5 6 //每5秒采用一次,共采樣6次。
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/2009
07:40:17 PM CPU %user %nice %system %iowait %steal %idle
07:40:19 PM all 12.44 0.00 6.97 1.74 0.00 78.86
07:40:21 PM all 26.75 0.00 12.50 16.00 0.00 44.75
07:40:23 PM all 16.96 0.00 7.98 0.00 0.00 75.06
參數詳解:
大部分的參數同mpstat top等命令。
%idle :等同於vmstat 中的id .就是空閒CPU百分比.如果該值高,表明CPU較空閒,但是處理速度還是很慢,則表明CPU在等待內存分配,應該加大服務器的內存。若是該值持續低於10%,表明CPU處理能力較弱,需要增加CPU。
%steal:管理程序維護另一個虛擬處理器時,虛擬CPU的無意識等待時間百分比。
5.iostat 主要是為了查看磁盤IO
Linux 2.6.16.46-0.12-smp (iread-85) 03/29/2010
avg-cpu: %user %nice %system %iowait %steal %idle
9.47 0.00 1.59 1.27 0.00 86.67
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 15.46 114.45 401.22 44378459 155576936
參數詳解:
avg-cpu中參數不做過多解釋,詳細可見其他命令,類似。
rrqm/s: 每秒進行 merge 的讀操作數目。即 delta(rmerge)/s
wrqm/s: 每秒進行 merge 的寫操作數目。即 delta(wmerge)/s
r/s: 每秒完成的讀 I/O 設備次數。即 delta(rio)/s
w/s: 每秒完成的寫 I/O 設備次數。即 delta(wio)/s
rsec/s: 每秒讀扇區數。即 delta(rsect)/s
wsec/s: 每秒寫扇區數。即 delta(wsect)/s
rkB/s: 每秒讀K字節數。是 rsect/s 的一半,因為每扇區大小為512字節。(需要計算)
wkB/s: 每秒寫K字節數。是 wsect/s 的一半。(需要計算)
avgrq-sz:平均每次設備I/O操作的數據大小 (扇區)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O隊列長度。即 delta(aveq)/s/1000 (因為aveq的單位為毫秒)。
await: 平均每次設備I/O操作的等待時間 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次設備I/O操作的服務時間 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的時間用於 I/O 操作,或者說一秒中有多少時間 I/O 隊列是非空的。即 delta(use)/s/1000 (因為use的單位為毫秒)
如果 %util 接近 100%,說明產生的I/O請求太多,I/O系統已經滿負荷,該磁盤
可能存在瓶頸。
idle小於70% IO壓力就較大了,一般讀取速度有較多的wait.
同時可以結合vmstat 查看查看b參數(等待資源的進程數)和wa參數(IO等待所占用的CPU時間的百分比,高過30%時IO壓力高)
2. top //直接敲TOP即可。
//系統當前時間、啟動時間、當前登錄數、平均負載 1、5、15分鐘負載值
top – 19:43:46 up 4 days, 10:46, 7 users, load average: 0.25, 0.37, 0.38
//進程總數、運行進程數、休眠進程數、終止進程數、僵死進程數
Tasks: 222 total, 1 running, 221 sleeping, 0 stopped, 0 zombie
//用戶占用、系統占用、優先線程占用、閒置線程占用、
Cpu(s): 0.3%us, 0.1%sy, 0.0%ni, 98.5%id, 1.0%wa, 0.0%hi, 0.1%si, 0.0%st
//內存狀態(總內存、已用內存、閒置內存、緩存使用內容)
Mem: 8183648k total, 8124052k used, 59596k free, 115072k buffers
//交換內存(總交換內存、已用內存、閒置內存、高速緩存容量)
Swap: 2104472k total, 1369376k used, 735096k free, 1462236k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 16 0 784 72 40 S 0 0.0 0:06.28 init
2 root RT 0 0 0 0 S 0 0.0 0:00.08 migration/0
3 root 34 19 0 0 0 S 0 0.0 0:00.01 ksoftirqd/0
4 root RT 0 0 0 0 S 0 0.0 0:00.29 migration/1
5 root 34 19 0 0 0 S 0 0.0 0:00.00 ksoftirqd/1
6 root RT 0 0 0 0 S 0 0.0 0:00.21 migration/2
7 root 34 19 0 0 0 S 0 0.0 0:00.05 ksoftirqd/2
8 root RT 0 0 0 0 S 0 0.0 0:00.08 migration/3
9 root 34 19 0 0 0 S 0 0.0 0:00.01 ksoftirqd/3
10 root 10 -5 0 0 0 S 0 0.0 0:00.02 events/0
11 root 10 -5 0 0 0 S 0 0.0 0:00.00 events/1
參數詳解:top命令式將系統最敏感的參數信息列出來。
PR :系統進程的分配的處理時間,若是16,則表示分配了16*10毫秒的時間長度來處理該線程。數值越大,代表處理時間越長。
NI :該進程的優先級
RES :該進程占用的物理內存的總數量,單位是KB。
SHR(SHARE) :該進程使用共享內存的數量。單位是KB
S(STAT) :該線程的狀態
S:代表休眠狀態;
D:代表不可中斷的休眠狀態;
R:代表運行狀態;
Z:代表僵死狀態;
T:代表停止或跟蹤狀態。
%CPU :該進程自最近一次刷新以來所占用的CPU時間和總時間的百分比
%MEM :該進程占用的物理內存占總內存的百分比。
TIME+:該線程啟動以來,占CPU的時間
常見用法:
top -d 3 //每三秒刷新一次數據 默認是每5秒刷新一次數據
Ctrl+L //擦除並且重寫屏幕。
概念詳解:
load average:
可以理解為每秒鐘CPU等待運行的進程個數.
在Linux系統中,sar -q、uptime、w、top等命令都會有系統平均負載load average的輸出,那麼什麼是系統平均負載呢?
系統平均負載被定義為在特定時間間隔內運行隊列中的平均任務數。如果一個進程滿足以下條件則其就會位於運行隊列中:
- 它沒有在等待I/O操作的結果
- 它沒有主動進入等待狀態(也就是沒有調用’wait’)
- 沒有被停止(例如:等待終止)
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的 iostat 輸出表明秒有 28.57 次設備 I/O 操作: 總IO(io)/s = r/s(讀) +w/s(寫) = 1.02+27.55 = 28.57 (次/秒) 其中寫操作占了主體 (w:r = 27:1)。
平均每次設備 I/O 操作只需要 5ms 就可以完成,但每個 I/O 請求卻需要等上 78ms,為什麼? 因為發出的 I/O 請求太多 (每秒鐘約 29 個),假設這些請求是同時發出的,那麼平均等待時間可以這樣計算:
平均等待時間 = 單個 I/O 服務時間 * ( 1 + 2 + … + 請求總數-1) / 請求總數
應用到上面的例子: 平均等待時間 = 5ms * (1+2+…+28)/29 = 70ms,和 iostat 給出的78ms 的平均等待時間很接近。這反過來表明 I/O 是同時發起的。
每秒發出的 I/O 請求很多 (約 29 個),平均隊列卻不長 (只有 2 個 左右),這表明這 29 個請求的到來並不均勻,大部分時間 I/O 是空閒的。
一秒中有 14.29% 的時間 I/O 隊列中是有請求的,也就是說,85.71% 的時間裡 I/O 系統無事可做,所有 29 個 I/O 請求都在142毫秒之內處理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s =78.21 * delta(io)/s = 78.21*28.57 = 2232.8,表明每秒內的I/O請求總共需要等待2232.8ms。所以平均隊列長度應為 2232.8ms/1000ms = 2.23,而 iostat 給出的平均隊列長度 (avgqu-sz) 卻為 22.35,為什麼?! 因為 iostat 中有 bug,avgqu-sz 值應為 2.23,而不是 22.35。