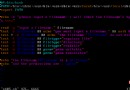
由於awk數組,是關聯數組。for…in循環輸出時候,默認打印出來是無序數組。
[chengmo@localhost ~]$ awk 'BEGIN{info = "this is a test";split(info,tA," ");for(k in tA){print k,tA[k];}}'
4 test
1 this
2 is
3 a
如果需要按照順序輸出,通過鍵值定位方式輸出。
[chengmo@localhost ~]$ awk 'BEGIN{info = "this is a test";slen=split(info,tA," ");for(i=1;i<=slen;i++){print i,tA[i];}}'
1 this
2 is
3 a
4 test
一、通過內置函數(asort,asorti使用) awk 3.1以上版本才支持
- asort使用說明
srcarrlen=asort[srcarr,dscarr] 默認返回值是:原數組長度,傳入參數dscarr則將排序後數組賦值給dscarr.
[chengmo@localhost ~]$ awk 'BEGIN{
a[100]=100;
a[2]=224;
a[3]=34;
slen=asort(a,tA);
for(i=1;i<=slen;i++)
{print i,tA[i];}
}'
1 34
2 100
3 224asort只對值進行了排序,因此丟掉原先鍵值。
2、asorti 使用說明
[chengmo@localhost ~]$ awk 'BEGIN{
a["d"]=100;
a["a"]=224;
a["c"]=34;
slen=asorti(a,tA);
for(i=1;i<=slen;i++)
{print i,tA[i],a[tA[i]];}
}'
1 a 224
2 c 34
3 d 100asorti對鍵值 進行排序(字符串類型),將生成新的數組放入:tA中。
二、通過管道發送到sort排序
[chengmo@localhost ~]$awk 'BEGIN{
a[100]=100;
a[2]=224;
a[3]=34;
for(i in a)
{print i,a[i] | "sort -r -n -k2";}
}'
2 224
100 100
3 34
通過管道,發送到外部程序“sort”排序,-r 從大到小,-n 按照數字排序,-k2 以第2列排序。通過將數據丟給第3方的sort命令,所有問題變得非常簡單。如果以key值排序 –k2 變成 -k1即可。
[chengmo@localhost ~]$ awk 'BEGIN{
a[100]=100;
a[2]=224;
a[3]=34;
for(i in a)
{print i,a[i] | "sort -r -n -k1";}
}'
100 100
3 34
2 224
三、自定義排序函數
function funname(p1,p2,p3)
{
staction;
return value;
}
以上是:awk自定義函數表示方式,默認傳入參數都是以引用方式傳入,return值,只能是字符型或者數值型。 不能返回數組類型。 如果返回數組類型。需要通過形參 方式傳入。再獲得。
awk返回數組類型
awk 'function test(ary){
for(i=0;i<10;i++){
ary[i]=i;
}
return i;
}
BEGIN{
n=test(array);
for(i=0;i<n;i++){
print array[i];
}
}
'
#arr 傳入一維數組
#key 排序類型 1是按照值排序 2按照鍵值
#datatype 比較類型 1按照數字排序 2按照字符串排序
#tarr 排序返回的數組
#splitseq 分割字符串 數組中鍵與值之間分割字符串
#return 數組長度
#實現思路,將原始數組a[‘a’]=100 排序後變成 a[1]=a分隔符100 ,然後按照下標遞歸顯示內容。 本排序使用冒泡方式進行。
function sortArr(arr,key,datatype,tarr,splitseq)
{if(key ~ /[^1-2]/)
{return tarr;}
for(k in arr)
{
tarr[++alen]=(k""splitseq""arr[k]);
}for(m=1;m<=alen;m++)
{
for(n=1;n<=alen-m-1;n++)
{
split(tarr[m],tm,splitseq);
split(tarr[n+1],tn,splitseq);tnum=tarr[m];
if(datatype==1)
{
if(tm[key]+0<tn[key]+0)
{
tarr[m]=tarr[n+1];
tarr[n+1]=tnum;
}
}
else
{
if((tm[key]"") < (tn[key]""))
{
tarr[m]=tarr[n+1];
tarr[n+1]=tnum;
}
}
}
}
return alen;
}
完整代碼如下:
[chengmo@centos5 ~]$ awk 'BEGIN{
a["a"]=100;
a["b"]=110;
a["c"]=10;
splitseq="%%";
alen=sortArr(a,2,1,tarr,splitseq);
for(m=1;m<=alen;m++)
{
split(tarr[m],ta,splitseq);
print m,ta[1],ta[2];
}
}
function sortArr(arr,key,datatype,tarr,splitseq)
{if(key ~ /[^1-2]/)
{return tarr;}
for(k in arr)
{
tarr[++alen]=(k""splitseq""arr[k]);
}for(m=1;m<=alen;m++)
{
for(n=1;n<=alen-m-1;n++)
{
split(tarr[m],tm,splitseq);
split(tarr[n+1],tn,splitseq);tnum=tarr[m];
if(datatype==1)
{
if(tm[key]+0<tn[key]+0)
{
tarr[m]=tarr[n+1];
tarr[n+1]=tnum;
}
}
else
{
if((tm[key]"") < (tn[key]""))
{
tarr[m]=tarr[n+1];
tarr[n+1]=tnum;
}
}
}
}
return alen;
}
'1 b 110
2 a 100
3 c 10
以上是awk數組排序一些方法。對於少量數據排序,就性能而言,使用自定義函數性能要高,不需要另外再開啟進程。對於大量數據,排序第2種方法還是很不錯的。