一、簡介
作為最基本的編程語言之一,匯編語言雖然應用的范圍不算很廣,但重要性卻勿庸置疑,因為它能夠完成許多其它語言所無法完成的功能。就拿 Linux 內核來講,雖然絕大部分代碼是用 C 語言編寫的,但仍然不可避免地在某些關鍵地方使用了匯編代碼,其中主要是在 Linux 的啟動部分。由於這部分代碼與硬件的關系非常密切,即使是 C 語言也會有些力不從心,而匯編語言則能夠很好揚長避短,最大限度地發揮硬件的性能。
大多數情況下 Linux 程序員不需要使用匯編語言,因為即便是硬件驅動這樣的底層程序在 Linux 操作系統中也可以用完全用 C 語言來實現,再加上 GCC 這一優秀的編譯器目前已經能夠對最終生成的代碼進行很好的優化,的確有足夠的理由讓我們可以暫時將匯編語言拋在一邊了。但實現情況是 Linux 程序員有時還是需要使用匯編,或者不得不使用匯編,理由很簡單:精簡、高效和 libc 無關性。假設要移植 Linux 到某一特定的嵌入式硬件環境下,首先必然面臨如何減少系統大小、提高執行效率等問題,此時或許只有匯編語言能幫上忙了。
匯編語言直接同計算機的底層軟件甚至硬件進行交互,它具有如下一些優點:
同時還應該認識到,匯編語言是一種層次非常低的語言,它僅僅高於直接手工編寫二進制的機器指令碼,因此不可避免地存在一些缺點:
Linux 下用匯編語言編寫的代碼具有兩種不同的形式。第一種是完全的匯編代碼,指的是整個程序全部用匯編語言編寫。盡管是完全的匯編代碼,Linux 平台下的匯編工具也吸收了 C 語言的長處,使得程序員可以使用 #include、#ifdef 等預處理指令,並能夠通過宏定義來簡化代碼。第二種是內嵌的匯編代碼,指的是可以嵌入到C語言程序中的匯編代碼片段。雖然 ANSI 的 C 語言標准中沒有關於內嵌匯編代碼的相應規定,但各種實際使用的 C 編譯器都做了這方面的擴充,這其中當然就包括 Linux 平台下的 GCC。
二、Linux 匯編語法格式
絕大多數 Linux 程序員以前只接觸過DOS/Windows 下的匯編語言,這些匯編代碼都是 Intel 風格的。但在 Unix 和 Linux 系統中,更多采用的還是 AT&T 格式,兩者在語法格式上有著很大的不同:
在 AT&T 匯編格式中,寄存器名要加上 '%' 作為前綴;而在 Intel 匯編格式中,寄存器名不需要加前綴。例如:
AT&T 格式 Intel 格式 pushl %eax push eax
在 AT&T 匯編格式中,用 '$' 前綴表示一個立即操作數;而在 Intel 匯編格式中,立即數的表示不用帶任何前綴。例如:
AT&T 格式 Intel 格式 pushl $1 push 1
AT&T 和 Intel 格式中的源操作數和目標操作數的位置正好相反。在 Intel 匯編格式中,目標操作數在源操作數的左邊;而在 AT&T 匯編格式中,目標操作數在源操作數的右邊。例如:
AT&T 格式 Intel 格式 addl $1, %eax add eax, 1
在 AT&T 匯編格式中,操作數的字長由操作符的最後一個字母決定,後綴'b'、'w'、'l'分別表示操作數為字節(byte,8 比特)、字(word,16 比特)和長字(long,32比特);而在 Intel 匯編格式中,操作數的字長是用 "byte ptr" 和 "word ptr" 等前綴來表示的。例如:
AT&T 格式 Intel 格式 movb val, %al mov al, byte ptr val
遠程轉移指令和遠程子調用指令的操作碼,在 AT&T 匯編格式中為 "ljump" 和 "lcall",而在 Intel 匯編格式中則為 "jmp far" 和 "call far",即:
AT&T 格式 Intel 格式 ljump $section, $offset jmp far section:offset lcall $section, $offset call far section:offset
與之相應的遠程返回指令則為:
AT&T 格式 Intel 格式 lret $stack_adjust ret far stack_adjust
在 AT&T 匯編格式中,內存操作數的尋址方式是
section:disp(base, index, scale)
而在 Intel 匯編格式中,內存操作數的尋址方式為:
section:[base + index*scale + disp]
由於 Linux 工作在保護模式下,用的是 32 位線性地址,所以在計算地址時不用考慮段基址和偏移量,而是采用如下的地址計算方法:
disp + base + index * scale
下面是一些內存操作數的例子:
AT&T 格式 Intel 格式 movl -4(%ebp), %eax mov eax, [ebp - 4] movl array(, %eax, 4), %eax mov eax, [eax*4 + array] movw array(%ebx, %eax, 4), %cx mov cx, [ebx + 4*eax + array] movb $4, %fs:(%eax) mov fs:eax, 4
三、Hello World!
真不知道打破這個傳統會帶來什麼樣的後果,但既然所有程序設計語言的第一個例子都是在屏幕上打印一個字符串 "Hello World!",那我們也以這種方式來開始介紹 Linux 下的匯編語言程序設計。
在 Linux 操作系統中,你有很多辦法可以實現在屏幕上顯示一個字符串,但最簡潔的方式是使用 Linux 內核提供的系統調用。使用這種方法最大的好處是可以直接和操作系統的內核進行通訊,不需要鏈接諸如 libc 這樣的函數庫,也不需要使用 ELF 解釋器,因而代碼尺寸小且執行速度快。
Linux 是一個運行在保護模式下的 32 位操作系統,采用 flat memory 模式,目前最常用到的是 ELF 格式的二進制代碼。一個 ELF 格式的可執行程序通常劃分為如下幾個部分:.text、.data 和 .bss,其中 .text 是只讀的代碼區,.data 是可讀可寫的數據區,而 .bss 則是可讀可寫且沒有初始化的數據區。代碼區和數據區在 ELF 中統稱為 section,根據實際需要你可以使用其它標准的 section,也可以添加自定義 section,但一個 ELF 可執行程序至少應該有一個 .text 部分。下面給出我們的第一個匯編程序,用的是 AT&T 匯編語言格式:
例1. AT&T 格式
#hello.s
.data # 數據段聲明
msg : .string "Hello, world!\\n" # 要輸出的字符串
len = . - msg # 字串長度
.text # 代碼段聲明
.global _start # 指定入口函數
_start: # 在屏幕上顯示一個字符串
movl $len, %edx # 參數三:字符串長度
movl $msg, %ecx # 參數二:要顯示的字符串
movl $1, %ebx # 參數一:文件描述符(stdout)
movl $4, %eax # 系統調用號(sys_write)
int $0x80 # 調用內核功能
# 退出程序
movl $0,%ebx # 參數一:退出代碼
movl $1,%eax # 系統調用號(sys_exit)
int $0x80 # 調用內核功能
初次接觸到 AT&T 格式的匯編代碼時,很多程序員都認為太晦澀難懂了,沒有關系,在 Linux 平台上你同樣可以使用 Intel 格式來編寫匯編程序:
例2. Intel 格式
; hello.asm
section .data ; 數據段聲明
msg db "Hello, world!", 0xA ; 要輸出的字符串
len equ $ - msg ; 字串長度
section .text ; 代碼段聲明
global _start ; 指定入口函數
_start: ; 在屏幕上顯示一個字符串
mov edx, len ; 參數三:字符串長度
mov ecx, msg ; 參數二:要顯示的字符串
mov ebx, 1 ; 參數一:文件描述符(stdout)
mov eax, 4 ; 系統調用號(sys_write)
int 0x80 ; 調用內核功能
; 退出程序
mov ebx, 0 ; 參數一:退出代碼
mov eax, 1 ; 系統調用號(sys_exit)
int 0x80 ; 調用內核功能
上面兩個匯編程序采用的語法雖然完全不同,但功能卻都是調用 Linux 內核提供的 sys_write 來顯示一個字符串,然後再調用 sys_exit 退出程序。在 Linux 內核源文件 include/asm-i386/unistd.h 中,可以找到所有系統調用的定義。
四、Linux 匯編工具
Linux 平台下的匯編工具雖然種類很多,但同 DOS/Windows 一樣,最基本的仍然是匯編器、連接器和調試器。
1.匯編器
匯編器(assembler)的作用是將用匯編語言編寫的源程序轉換成二進制形式的目標代碼。Linux 平台的標准匯編器是 GAS,它是 GCC 所依賴的後台匯編工具,通常包含在 binutils 軟件包中。GAS 使用標准的 AT&T 匯編語法,可以用來匯編用 AT&T 格式編寫的程序:
[xiaowp@gary code]$ as -o hello.o hello.s
Linux 平台上另一個經常用到的匯編器是 NASM,它提供了很好的宏指令功能,並能夠支持相當多的目標代碼格式,包括 bin、a.out、coff、elf、rdf 等。NASM 采用的是人工編寫的語法分析器,因而執行速度要比 GAS 快很多,更重要的是它使用的是 Intel 匯編語法,可以用來編譯用 Intel 語法格式編寫的匯編程序:
[xiaowp@gary code]$ nasm -f elf hello.asm
2.鏈接器
由匯編器產生的目標代碼是不能直接在計算機上運行的,它必須經過鏈接器的處理才能生成可執行代碼。鏈接器通常用來將多個目標代碼連接成一個可執行代碼,這樣可以先將整個程序分成幾個模塊來單獨開發,然後才將它們組合(鏈接)成一個應用程序。 Linux 使用 ld 作為標准的鏈接程序,它同樣也包含在 binutils 軟件包中。匯編程序在成功通過 GAS 或 NASM 的編譯並生成目標代碼後,就可以使用 ld 將其鏈接成可執行程序了:
[xiaowp@gary code]$ ld -s -o hello hello.o
3.調試器
有人說程序不是編出來而是調出來的,足見調試在軟件開發中的重要作用,在用匯編語言編寫程序時尤其如此。Linux 下調試匯編代碼既可以用 GDB、DDD 這類通用的調試器,也可以使用專門用來調試匯編代碼的 ALD(Assembly Language Debugger)。
從調試的角度來看,使用 GAS 的好處是可以在生成的目標代碼中包含符號表(symbol table),這樣就可以使用 GDB 和 DDD 來進行源碼級的調試了。要在生成的可執行程序中包含符號表,可以采用下面的方式進行編譯和鏈接:
[xiaowp@gary code]$ as --gstabs -o hello.o hello.s [xiaowp@gary code]$ ld -o hello hello.o
執行 as 命令時帶上參數 --gstabs 可以告訴匯編器在生成的目標代碼中加上符號表,同時需要注意的是,在用 ld 命令進行鏈接時不要加上 -s 參數,否則目標代碼中的符號表在鏈接時將被刪去。
在 GDB 和 DDD 中調試匯編代碼和調試 C 語言代碼是一樣的,你可以通過設置斷點來中斷程序的運行,查看變量和寄存器的當前值,並可以對代碼進行單步跟蹤。圖1 是在 DDD 中調試匯編代碼時的情景:
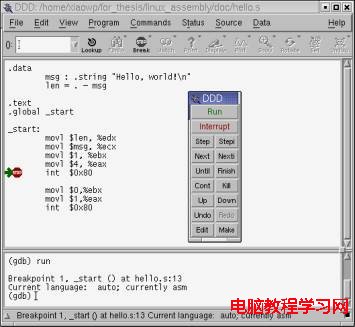
圖1 用 DDD 中調試匯編程序
匯編程序員通常面對的都是一些比較苛刻的軟硬件環境,短小精悍的ALD可能更能符合實際的需要,因此下面主要介紹一下如何用ALD來調試匯編程序。首先在命令行方式下執行ald命令來啟動調試器,該命令的參數是將要被調試的可執行程序:
[xiaowp@gary doc]$ ald hello Assembly Language Debugger 0.1.3 Copyright (C) 2000-2002 Patrick Alken hello: ELF Intel 80386 (32 bit), LSB, Executable, Version 1 (current) Loading debugging symbols...(15 symbols loaded) ald>
當 ALD 的提示符出現之後,用 disassemble 命令對代碼段進行反匯編:
ald> disassemble -s .text Disassembling section .text (0x08048074 - 0x08048096) 08048074 BA0F000000 mov edx, 0xf 08048079 B998900408 mov ecx, 0x8049098 0804807E BB01000000 mov ebx, 0x1 08048083 B804000000 mov eax, 0x4 08048088 CD80 int 0x80 0804808A BB00000000 mov ebx, 0x0 0804808F B801000000 mov eax, 0x1 08048094 CD80 int 0x80
上述輸出信息的第一列是指令對應的地址碼,利用它可以設置在程序執行時的斷點:
ald> break 0x08048088 Breakpoint 1 set for 0x08048088
斷點設置好後,使用 run 命令開始執行程序。ALD 在遇到斷點時將自動暫停程序的運行,同時會顯示所有寄存器的當前值:
ald> run Starting program: hello Breakpoint 1 encountered at 0x08048088 eax = 0x00000004 ebx = 0x00000001 ecx = 0x08049098 edx = 0x0000000F esp = 0xBFFFF6C0 ebp = 0x00000000 esi = 0x00000000 edi = 0x00000000 ds = 0x0000002B es = 0x0000002B fs = 0x00000000 gs = 0x00000000 ss = 0x0000002B cs = 0x00000023 eip = 0x08048088 eflags = 0x00000246 Flags: PF ZF IF 08048088 CD80 int 0x80
如果需要對匯編代碼進行單步調試,可以使用 next 命令:
ald> next Hello, world! eax = 0x0000000F ebx = 0x00000000 ecx = 0x08049098 edx = 0x0000000F esp = 0xBFFFF6C0 ebp = 0x00000000 esi = 0x00000000 edi = 0x00000000 ds = 0x0000002B es = 0x0000002B fs = 0x00000000 gs = 0x00000000 ss = 0x0000002B cs = 0x00000023 eip = 0x0804808F eflags = 0x00000346 Flags: PF ZF TF IF 0804808F B801000000 mov eax, 0x1
若想獲得 ALD 支持的所有調試命令的詳細列表,可以使用 help 命令:
ald> help Commands may be abbreviated. If a blank command is entered, the last command is repeated. Type `help <command>' for more specific information on <command>. General commands attach clear continue detach disassemble enter examine file help load next quit register run set step unload window write Breakpoint related commands break delete disable enable ignore lbreak tbreak
五、系統調用
即便是最簡單的匯編程序,也難免要用到諸如輸入、輸出以及退出等操作,而要進行這些操作則需要調用操作系統所提供的服務,也就是系統調用。除非你的程序只完成加減乘除等數學運算,否則將很難避免使用系統調用,事實上除了系統調用不同之外,各種操作系統的匯編編程往往都是很類似的。
在 Linux 平台下有兩種方式來使用系統調用:利用封裝後的 C 庫(libc)或者通過匯編直接調用。其中通過匯編語言來直接調用系統調用,是最高效地使用 Linux 內核服務的方法,因為最終生成的程序不需要與任何庫進行鏈接,而是直接和內核通信。
和 DOS 一樣,Linux 下的系統調用也是通過中斷(int 0x80)來實現的。在執行 int 80 指令時,寄存器 eax 中存放的是系統調用的功能號,而傳給系統調用的參數則必須按順序放到寄存器 ebx,ecx,edx,esi,edi 中,當系統調用完成之後,返回值可以在寄存器 eax 中獲得。
所有的系統調用功能號都可以在文件 /usr/include/bits/syscall.h 中找到,為了便於使用,它們是用 SYS_<name> 這樣的宏來定義的,如 SYS_write、SYS_exit 等。例如,經常用到的 write 函數是如下定義的:
ssize_t write(int fd, const void *buf, size_t count);
該函數的功能最終是通過 SYS_write 這一系統調用來實現的。根據上面的約定,參數 fb、buf 和 count 分別存在寄存器 ebx、ecx 和 edx 中,而系統調用號 SYS_write 則放在寄存器 eax 中,當 int 0x80 指令執行完畢後,返回值可以從寄存器 eax 中獲得。
或許你已經發現,在進行系統調用時至多只有 5 個寄存器能夠用來保存參數,難道所有系統調用的參數個數都不超過 5 嗎?當然不是,例如 mmap 函數就有 6 個參數,這些參數最後都需要傳遞給系統調用 SYS_mmap:
void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset);
當一個系統調用所需的參數個數大於 5 時,執行int 0x80 指令時仍需將系統調用功能號保存在寄存器 eax 中,所不同的只是全部參數應該依次放在一塊連續的內存區域裡,同時在寄存器 ebx 中保存指向該內存區域的指針。系統調用完成之後,返回值仍將保存在寄存器 eax 中。
由於只是需要一塊連續的內存區域來保存系統調用的參數,因此完全可以像普通的函數調用一樣使用棧(stack)來傳遞系統調用所需的參數。但要注意一點,Linux 采用的是 C 語言的調用模式,這就意味著所有參數必須以相反的順序進棧,即最後一個參數先入棧,而第一個參數則最後入棧。如果采用棧來傳遞系統調用所需的參數,在執行int 0x80 指令時還應該將棧指針的當前值復制到寄存器 ebx中。
六、命令行參數
在 Linux 操作系統中,當一個可執行程序通過命令行啟動時,其所需的參數將被保存到棧中:首先是 argc,然後是指向各個命令行參數的指針數組 argv,最後是指向環境變量的指針數據 envp。在編寫匯編語言程序時,很多時候需要對這些參數進行處理,下面的代碼示范了如何在匯編代碼中進行命令行參數的處理:
例3. 處理命令行參數
# args.s
.text
.globl _start
_start:
popl %ecx # argc
vnext:
popl %ecx # argv
test %ecx, %ecx # 空指針表明結束
jz exit
movl %ecx, %ebx
xorl %edx, %edx
strlen:
movb (%ebx), %al
inc %edx
inc %ebx
test %al, %al
jnz strlen
movb $10, -1(%ebx)
movl $4, %eax # 系統調用號(sys_write)
movl $1, %ebx # 文件描述符(stdout)
int $0x80
jmp vnext
exit:
movl $1,%eax # 系統調用號(sys_exit)
xorl %ebx, %ebx # 退出代碼
int $0x80
ret
七、GCC 內聯匯編
用匯編編寫的程序雖然運行速度快,但開發速度非常慢,效率也很低。如果只是想對關鍵代碼段進行優化,或許更好的辦法是將匯編指令嵌入到 C 語言程序中,從而充分利用高級語言和匯編語言各自的特點。但一般來講,在 C 代碼中嵌入匯編語句要比"純粹"的匯編語言代碼復雜得多,因為需要解決如何分配寄存器,以及如何與C代碼中的變量相結合等問題。
GCC 提供了很好的內聯匯編支持,最基本的格式是:
__asm__("asm statements");
例如:
__asm__("nop");
如果需要同時執行多條匯編語句,則應該用"\\n\\t"將各個語句分隔開,例如:
__asm__( "pushl %%eax \\n\\t"
"movl $0, %%eax \\n\\t"
"popl %eax");
通常嵌入到 C 代碼中的匯編語句很難做到與其它部分沒有任何關系,因此更多時候需要用到完整的內聯匯編格式:
__asm__("asm statements" : outputs : inputs : registers-modified);
插入到 C 代碼中的匯編語句是以":"分隔的四個部分,其中第一部分就是匯編代碼本身,通常稱為指令部,其格式和在匯編語言中使用的格式基本相同。指令部分是必須的,而其它部分則可以根據實際情況而省略。
在將匯編語句嵌入到C代碼中時,操作數如何與C代碼中的變量相結合是個很大的問題。GCC采用如下方法來解決這個問題:程序員提供具體的指令,而對寄存器的使用則只需給出"樣板"和約束條件就可以了,具體如何將寄存器與變量結合起來完全由GCC和GAS來負責。
在GCC內聯匯編語句的指令部中,加上前綴'%'的數字(如%0,%1)表示的就是需要使用寄存器的"樣板"操作數。指令部中使用了幾個樣板操作數,就表明有幾個變量需要與寄存器相結合,這樣GCC和GAS在編譯和匯編時會根據後面給定的約束條件進行恰當的處理。由於樣板操作數也使用'%'作為前綴,因此在涉及到具體的寄存器時,寄存器名前面應該加上兩個'%',以免產生混淆。
緊跟在指令部後面的是輸出部,是規定輸出變量如何與樣板操作數進行結合的條件,每個條件稱為一個"約束",必要時可以包含多個約束,相互之間用逗號分隔開就可以了。每個輸出約束都以'='號開始,然後緊跟一個對操作數類型進行說明的字後,最後是如何與變量相結合的約束。凡是與輸出部中說明的操作數相結合的寄存器或操作數本身,在執行完嵌入的匯編代碼後均不保留執行之前的內容,這是GCC在調度寄存器時所使用的依據。
輸出部後面是輸入部,輸入約束的格式和輸出約束相似,但不帶'='號。如果一個輸入約束要求使用寄存器,則GCC在預處理時就會為之分配一個寄存器,並插入必要的指令將操作數裝入該寄存器。與輸入部中說明的操作數結合的寄存器或操作數本身,在執行完嵌入的匯編代碼後也不保留執行之前的內容。
有時在進行某些操作時,除了要用到進行數據輸入和輸出的寄存器外,還要使用多個寄存器來保存中間計算結果,這樣就難免會破壞原有寄存器的內容。在GCC內聯匯編格式中的最後一個部分中,可以對將產生副作用的寄存器進行說明,以便GCC能夠采用相應的措施。
下面是一個內聯匯編的簡單例子:
例4.內聯匯編
/* inline.c */
int main()
{
int a = 10, b = 0;
__asm__ __volatile__("movl %1, %%eax;\\n\\r"
"movl %%eax, %0;"
:"=r"(b) /* 輸出 */
:"r"(a) /* 輸入 */
:"%eax"); /* 不受影響的寄存器 */
printf("Result: %d, %d\\n", a, b);
}
上面的程序完成將變量a的值賦予變量b,有幾點需要說明:
在內聯匯編中用到的操作數從輸出部的第一個約束開始編號,序號從0開始,每個約束記數一次,指令部要引用這些操作數時,只需在序號前加上'%'作為前綴就可以了。需要注意的是,內聯匯編語句的指令部在引用一個操作數時總是將其作為32位的長字使用,但實際情況可能需要的是字或字節,因此應該在約束中指明正確的限定符:
限定符 意義 "m"、"v"、"o" 內存單元 "r" 任何寄存器 "q" 寄存器eax、ebx、ecx、edx之一 "i"、"h" 直接操作數 "E"和"F" 浮點數 "g" 任意 "a"、"b"、"c"、"d" 分別表示寄存器eax、ebx、ecx和edx "S"和"D" 寄存器esi、edi "I" 常數(0至31)
八、小結
Linux操作系統是用C語言編寫的,匯編只在必要的時候才被人們想到,但它卻是減少代碼尺寸和優化代碼性能的一種非常重要的手段,特別是在與硬件直接交互的時候,匯編可以說是最佳的選擇。Linux提供了非常優秀的工具來支持匯編程序的開發,使用GCC的內聯匯編能夠充分地發揮C語言和匯編語言各自的優點。