Linux系統操作中,如果文件中的數據過多,想要刪除重復數據行是非常麻煩的,查找不方便,那麼有什麼方法能夠快速刪除文件重復數據行呢?下面小編就給大家介紹下如何刪除文件重復數據行,一起來看看吧。

一、去掉相鄰重復的數據行
代碼如下:
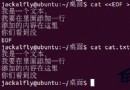
$cat data1.txt | uniq
輸出:
beijing
wuhan
beijing
wuhan
二、去掉所有重復的數據行
代碼如下:
$cat data1.txt | sort | uniq
注:
只有uniq命令的話,只是把相鄰的重復的數據行去掉。
如果先 sort 的話,就會把所有重復的數據行變成相鄰的數據行,再 uniq 的話,就去掉所有重復的數據行了。
輸出:
beijing
wuhan
附:data1.txt
代碼如下:
[root@syy ~]# cat data1.txt
beijing
beijing
wuhan
wuhan
wuhan
beijing
beijing
beijing
wuhan
wuhan
注:在過濾日志中的IP地址很有用。
Linux下刪除大數據文件中部分字段重復的行
最近寫的一個數據采集程序生成了一個含有1千多萬行數據的文件,數據由4個字段組成,按照要求需要刪除第二個字段重復的行,找來找去linux下也沒找到合適的工具,sed/gawk等流處理工具只能針對一行一行處理,並無法找到字段重復的行。看來只好自己python一個程序了,突然想起來利用mysql,於是進行乾坤大挪移:
1. 利用mysqlimport --local dbname data.txt導入數據到表中,表名要與文件名一致
2. 執行下列sql語句(要求唯一的字段為uniqfield)
代碼如下:
use dbname;
alter table tablename add rowid int auto_increment not null;
create table t select min(rowid) as rowid from tablename group by uniqfield;
create table t2 select tablename .* from tablename,t where tablename.rowid= t.rowid;《/p》 《p》drop table tablename;
rename table t2 to tablename;
上面就是Linux刪除文件重復數據行的方法介紹了,本文介紹了多種情況下刪除文件重復數據行的方法,希望對你有所幫助。