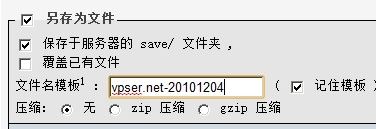
總的來講,bbr之前的擁塞控制邏輯在執行過程中會分為兩種階段,即正常階段和異常階段。在正常階段中,TCP模塊化的擁塞控制算法主導窗口的調整,在異常階段中,TCP核心的擁塞控制狀態機從擁塞控制算法那裡接管窗口的計算,在Linux的實現中,這是由以下邏輯表示的:
static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked,
int flag)
{
if (tcp_in_cwnd_reduction(sk)) { // 異常模式
/* Reduce cwnd if state mandates */
// 在進入窗口下降邏輯之前,還需要tcp_fastretrans_alert來搜集異常信息並處理異常過程。
tcp_cwnd_reduction(sk, acked_sacked, flag);
} else if (tcp_may_raise_cwnd(sk, flag)) { // 正常模式或者安全的異常模式!
/* Advance cwnd if state allows */
tcp_cong_avoid(sk, ack, acked_sacked);
}
tcp_update_pacing_rate(sk);
}
if (tcp_ack_is_dubious(sk, flag)) {
is_dupack = !(flag & (FLAG_SND_UNA_ADVANCED | FLAG_NOT_DUP));
tcp_fastretrans_alert(sk, acked, is_dupack, &flag, &rexmit);
}
static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked,
int flag, const struct rate_sample *rs)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
// 這裡是新邏輯,如果回調中宣稱自己有能力解決任何擁塞問題,那麼交給它!
if (icsk->icsk_ca_ops->cong_control) {
icsk->icsk_ca_ops->cong_control(sk, rs);
// 直接return!TCP核心不再過問。
return;
}
// 這是老的邏輯。
if (tcp_in_cwnd_reduction(sk)) {
/* Reduce cwnd if state mandates */
// 如果不是Open狀態...記住,tcp_cwnd_reduction並不受擁塞控制算法控制!!
tcp_cwnd_reduction(sk, acked_sacked, flag);
} else if (tcp_may_raise_cwnd(sk, flag)) {
/* Advance cwnd if state allows */
tcp_cong_avoid(sk, ack, acked_sacked);
}
tcp_update_pacing_rate(sk);
}
不基於數據反饋的預測都是假的,不真實的,騙人的。這就是為什麼基於大數據的人工智能比基於算法的人工智能更厲害的原因,算法再猛都是扯淡,只有數據才能訓練出聰明的模型。在TCP擁塞控制算法領域,CUBIC的三次凸凹函數看起來是那麼的晦澀卻顯得高大上,大多數人無力深究這個算法的細節,然而bbr算法卻是一個隨便什麼人都看得懂的....
bbr不斷采集連接內時間窗口內的最大帶寬max-bw和最小RTT min-rtt(見下面的win_minmax),並以此計算發送速率和擁塞窗口,依據反饋的實際帶寬bw和max-rtt調節增益系數。其背後的思想是,一旦在一個時間窗口內采集到更大的帶寬和更小的rtt,bbr就認為客觀上它們的乘積,即BDP是可以填充的客觀管道容量,並按此作為基准,萬一沒有達到,bbr會認為這是發生了擁塞,調小增益系數即可,但在時間窗口范圍內並不改變基准(時間局部性使然),由於增益系數是根據反饋調節的且基准BDP不變,一旦擁塞緩解,bbr可以第一時間發現並增大增益系數!
bbr能做到以上這些並工作地很好,全在於tcp擁塞狀態機控制邏輯不會打擾它的行為,而這些在之前的擁塞控制算法中幾乎是做不到的,比如CUBIC算法,一旦丟包,CUBIC便會被接管,直到Linux按照硬性標准判斷其TCP擁塞狀態已經恢復到了Open狀態。